协议设计
- Kafka自定义了一组基于TCP的二进制协议,用于实现各种消息相关操作
- 协议基本结构
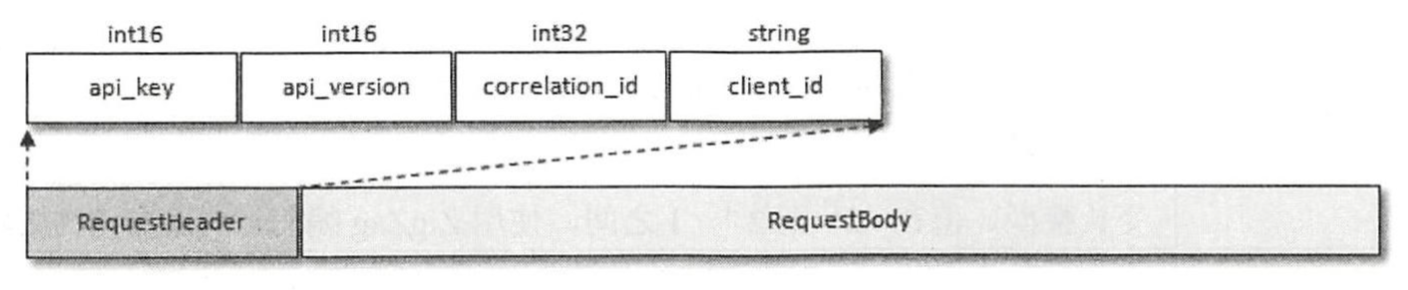

- 不同的api(PRODUCE、FETCH等),RequestBody和ResponseBody结构也不同,其详细描述可查阅6.1节
时间轮(TimingWheel)
Kafka基于时间轮概念自定义实现了一个用于延时功能的定时器(SystemTitmer)
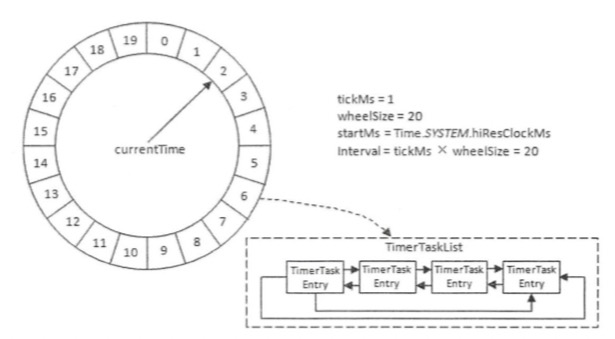
- 时间轮是一个存储定时任务的环形队列 ,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表( TimerTaskList)。TimerTaskList 是一个环形的双向链表,链表中的每一项表示的都是定时任务项( TimerTaskEntry),其中封装了真正的定时任务 (TimerTask) 。
- 时间轮由多个时间格组成,每个时间格代表基本时间跨度(titkMs),时间轮时间格个数(wheelSIze)是固定的。
- currentTime将时间轮划分为到期部分和未到期部分,当前指向的表示刚好到期,需要处理此时间格内的TimerTaskList中的任务
wheelSize的扩充有限制,当定时时间较大时,不能直接扩充wheelsize,这不仅会占用很大的内存空间,也会拉低效率。针对不同定时需要,Kafka引入层级时间轮的概念。
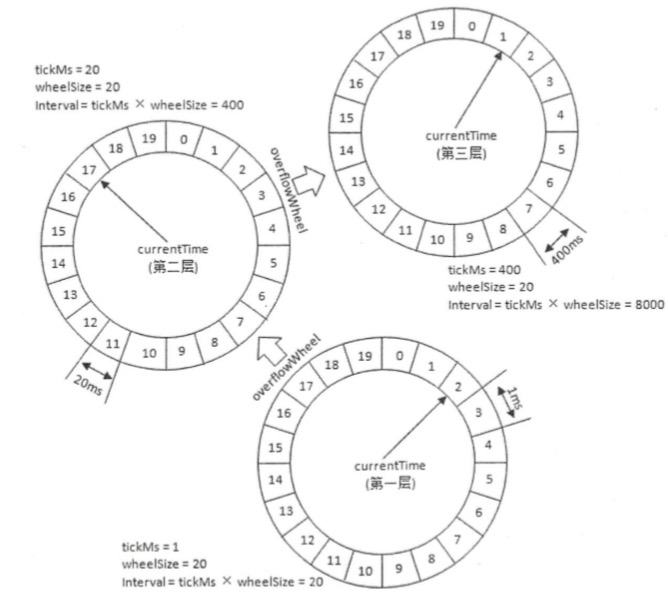
当任务的到期时间超过了当前时间轮的时间范围,会尝试添加到上层时间轮。当延时任务所在的时间轮不能精准实现到期时间时,也会重新提交到层级时间轮,进行降级。
降级示例:在到期时间为[400ms,800ms)区间内的多个任务(比如 446ms、455ms 和 473ms 的定时任务)都会被放入第三层时间轮的时间格1,时间格1对应的 TimerTaskList 的超时时间为 400ms。 随着时间的流逝,当此 TimerTaskList 到期之时,原本定时为 450ms 的任务还剩下 50ms 的时间,还不能执行这个任务的到期操作。这里就有一个时间轮降级的操作,会将这个剩余时间为 50ms 的定时任务重新提交到层级时间 轮中,此时第一层时间轮的总体时间跨度不够,而第二层足够,所以该任务被放到第二层时间轮到期时间为[40ms,60ms)的时间格中。 再经历40ms之后,此时这个任务又被“察觉”,不过 还剩余 lOms,还是不能立即执行到期操作。所以还要再有一次时间轮的降级,此任务被添加到 第一层时间轮到期时间为[1Oms,11ms)的时间格中,之后再经历 lOms后,此任务真正到期,最终执行相应的到期操作。
可以类比成时钟来理解。
Kafka中的定时器只持有第一层时间轮引用,每一层时间轮中有一个引用指向更高一层。
Kafka 中的定时器借了JDK中的DelayQueue来协助推进时间轮,具体做法如下:
- 每个使用到的TimerTaskList都加入DelayQueue,DelayQueue会根据TimerTaskList对应的超时时间expiration来排序
- Kafka有一个线程ExpiredOperationReaper(过期任务收割机)来获取DelayQueue中到期的任务列表
- 获取 DelayQueue中超时的任务列表 TimerTaskList 之后,既可以根据TimerTaskList的expiration来推进时间轮的时间,也可以就获取的TimerTaskList执行相应的操作,对里面的TimerTaskEntry该执行过期操作的就执行过期操作,该降级时间轮的就降级时间轮 。
delayqueue的原理
Kafka 中的定时器真可谓“知人善用” , 用 TimjngWheel做最擅长的任务添加和删除操作,而用DelayQueue做最擅长的时间推进工作,两者相辅相成 。
延时操作
延时操作(延时生产、延时拉取等)需要延时返回响应的结果
- 首先它必须有一个超时时间(delayMs),如果在这个超时时间内没有完成既定的任务,那么就需要强制完成以返回响应结果给客户端
- 其次,延时操作不同于定时操作,定时操作是指在特定时间之后执 行的操作,而延时操作可以在所设定的超时时间之前完成,所以延时操作能够支持外部事件的触发
Kafka中的延时操作创建后会被加入延时操作管理器(DelayedOperationPurgatory)做专门处理,每个延时操作管理器配别一个定时器(由时间轮实现)。延时操作除了满足时间条件执行,还支持外部事件触发,由一个监听池来监听每个分区的外部事件。
控制器(KafkaController)
Kafka集群中有一个broker会被选举为控制器,负责管理整个集群中所有分区和副本的状态。其职责有:
- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本
- 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息
- 当使用 kafka-topics.sh 脚本为某个topic增加分区数量时,同样还是由控制器负责分区的重新分配
控制器的选举及异常恢复
控制器选举
broker启动时尝试读取zk的/controller节点的brokerid,如果不为-1,则放弃竞选。如果不存在/controller节点或节点数据异常,broker会尝试创建此节点,多个broker只有创建成功的会成为控制器。
broker内存会保存当前控制器brokerid:activeControllerId
Kafka通过zk的controller_epoch来保证控制器的唯一性,其用于记录控制器发生变更的次数
每个和控制器交互的请求都会携带 controller epoch 这个宇段,如果请求的 controller_epoch 值小于内存中的 controller_epoch 值, 则认为这个请求是向己经过期的控制器所发送的请求,那么这个请求会被认定为无效的请求。 如果请求的 controller epoch 值大于内存中的 controller_epoch 值,那么说明 己经有 新的控制器当选了
异常恢复
- 当/controller节点的数据发生变化时,每个broker都会更新自身内存中保存的activeControllerld。如果broker在数据变更前是控制器,在数据变更后自身的brokerid值和新的activeControllerld值不一致,那么就需要“退位” ,关闭相应的资源,如关闭状态机、注销监听器。
- 当控制器由于异常下线或其他原因 导致/controller节点被删除时,每个 broker都会进行选举,如果 broker在节点被删除前 是控制器,那么在选举前还需要有 一个“退位”的动作。
优雅关闭
使用kafka-server-stop.sh脚本来优雅地关闭kafka,而不是使用jps加kill -9来关闭
- 该脚本会给kafka进程发送一个终止信号(TERM),kafka进程捕获该信号后会执行一个关闭钩子中的内容,其中除了关闭一些必要的资源,还会执行控制关闭(ControlledShutdown)的动作
- broker使用ControlledShutdown的方式关闭时
- 可以让消息完全同步到磁盘上,使服务下次上线时不需要进行日志的恢复操作
- 在关闭服务前会对其上的leader副本进行迁移,这样可以减少分区的不可用时间
分区leader的选举
分区leader副本的选举由控制器负责具体实施。其有四种不同的选举策略,这些策略应用于不同的场景。
OfflinePartitionLeaderElectionStrategy:
当创建分区或原leader副本下线采用,控制器使用该策略选举新的leader:
unclean.leader.election.enable为false时:按照AR集合顺序查找第一个存活的副本,且该副本在ISR集合中。unclean.leader.election.enable为true时:按照AR集合顺序查找第一个存活的副本。
注意AR顺序在分配时就被指定,只要不发生重分配就保持不变。而分区的ISR集合中副本的顺序可能会改变
ReassignPartitionLeaderElectionStrategy:
- 当分区重分配时采用,从重分配的AR中找到第一个存活的 replica,且满足在ISR中
PrefferredReplicaPartitionLeaderElectionStrategy:
- 优先副本选举时采用,直接将优先副本设置为leader
ControlledShutdownPartitionLeaderElectionStrategy:
- 当某节点被优雅关闭时采用,AR中找到第一个存活replica,且在ISR中,还要确保不在关闭的节点上
服务端参数
broker.id- broker启动前必须设定的参数,作为broker的唯一id。
- broker启动时会在zk的/brokers/ids下创建节点,broker的健康状态检查就依赖此节点,broker下线时此节点会自动删除
- 在 config/server.properties 或 meta.properties 中配置
- 可通过
broker.id.generation.enable(默认true) 和reserved.broker.max.id(默认1000) 来配合自动生成新的brokerId。自动生成的brokerId会大于maxid的配置。
bootstrap.servers这个参数用来配置发现kafka集群元数据信息的服务地址(可以不是broker)
客户端连接kafka集群的过程
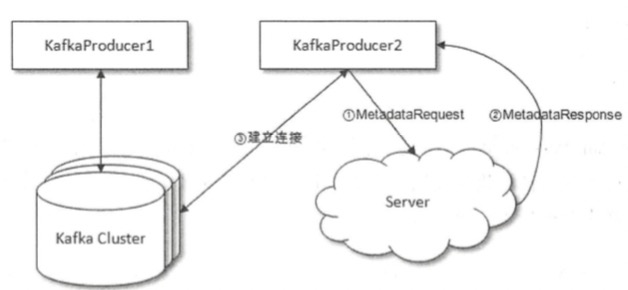
- 客户端与bootstrap.servers指定的server连接,发送MetadataRequest请求获取集群的元数据信息
- server收到请求后,返回MetadataResponse,其中包含集群元数据信息
- 客户端通过解析元数据信息,与集群各个节点建立连接
其他服务端参数列表
引:kafka brokers配置参数详解
