分区分配策略
消费者客户端可配置partition.assignment.strategy来设置消费者与topic之间的partition分配策略,默认org.apache.kafka.clients.consumer.RangeAssignor,可配置多个策略,逗号分隔。
RangeAssignor:
按照consumer总数和partition总数进行整除获得一个跨度,将partition按跨度进行平均分配,保证尽可能的均匀分配给所有consumer。分配时将consumerGroup内的consumer按名称字典排序,依次分配partition范围。
这里的consumer指的是消费组内订阅了分区所属主题的消费者
如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
RoundRobinAssignor:
- 将group内所有consumer和被订阅的所有topic的partition按字典序排序,通过轮询方式,逐个分配partition
- 如果同一个group内的consumer订阅信息是不相同的,可能导致partition分配不均匀。
StickyAssignor:
- 主要目的:partition分配尽可能均匀,分配partition尽可能与上次保持相同
- 比上述两个策略更加优异
自定义分配策略
- 实现PartitionAssignor接口
- 具体内容查阅7.1.4节
消费者协调器和组协调器
如果消费者客户端中配置了两个分配策略,那么以哪个为准呢?如果有多个消费者,彼此所配置的分配策略并不完全相同,那么以哪个为准?多个消费者之间的分区分配是需要协同的,那么这个协同的过程又是怎样的呢?这一切都是交由消费者协调器( ConsumerCoordinator )和组协调器(GroupCoordinator)来完成的,它们之间使用一套组协调协议进行交互。
旧版客户端问题
- 旧版消费者客户端使用zk的监听器(Watcher)来实现分区分配。consumer和broker状态发生变化时,相应的节点也会变化,客户端就能够监听到状态。
- 依赖zk有两个严重问题:
- 羊群效应:当监听的节点发生变化,大量Watcher通知发送到客户端,导致其他操作延迟,甚至发生死锁
- 脑裂问题:再均衡操作时,每个consumer与zk进行通信来监听变化情况,由于zk本身特性,可能导致同一时刻各个consumer获取的状态不一致,从而导致异常
新版客户端再均衡的原理
新版客户端将全部消费组分成多个子集,每个子集在服务端对应一个GroupCoordinator对其进行管理,而消费者客户端中使用ConsumerCoordinator组件与GroupCoordinator交互。
触发再均衡操作的情形有:
- 新的consumer加入group
- consumer宕机(长时间没有发送心跳)
- consumer主动退出group(unsubscrible())
- group对应的GroupCoorinator节点发生了变更
- group内订阅的任一topic或主题的partition数量发生变化
接下来以一个例子介绍再均衡的详细过程,当有消费者加入消费组时,消费者、消费组及组协调器之间会经历以下几个 阶段:
第一阶段(FIND_COORDINATOR)
consumer需要确定所属group对应的GroupCoordinator所在的broker,并创建与该broker通信的连接
如果已经保存了GroupCoordinator节点信息且连接正常,则进入第二阶段。否则,需要向集群中某个节点(leastLoadedNode)发送FindCoordinatorRequest来查找对应的GroupCoordinator
具体查找 GroupCoordinator的方式是先根据消费组groupid的哈希值计算_consumer_offsets 中的分区编号,然后寻找该分区leader副本所在的broker节点
第二阶段(JOIN_GROUP)
consumer会向GroupCoordinator发送JoinGroupRequest以加入消费组。
- JoinGroupRequest中包含该消费者设置的分配策略。
- 若该消费者是第一次加入该消费组,GroupCoordinator受到该请求后会为该消费者生成一个唯一标识
member_id
如果是原有consumer重新加入group,发送前还要执行一些准备工作:
enable.auto.commit为true时,需要向GroupCoordinator提交位移执行再均衡监听器(ConsumerRebalanceListener)的
onPartitionsRevoked()方法暂时禁止心跳检测运作
选举消费组的leader
GroupCoordinator需要为消费组内的consumer选举出一个leader。如果消费组内还没有leader,则第一个加入的consumer即为leader。如果原leader退出消费组,则重新选举leader(近乎随机)
在GroupCoordinator中消费者的信息是以HashMap的形式存储的,其中key为消费者的member id,而value是消费者相关的元数据信息。 leaderld表示leader消费者的member id,它的取值为HashMap中的第一个键值对的 key。
选举分区分配策略
- 每个consumer都可以设置自己的分区分配策略,而消费组需要从中选出一个来进行整体分区分配。
- 这个分区分配策略的选举是由消费组内的消费者投票来决定的。具体选举过程如下:
- 收集各个消费者支持的所有分配策略,组成候选集
- 组内的消费者从候选集中找出第一个自身支持的策略,并投上一票(不需要再次与组协调器交互,该步骤在组协调器内部完成)
- 计算候选集中个分配策略的票数,票数最高的策略即为当前消费组的分配策略
在此之后, Kafka 服务端就要发送 JoinGroupResponse 响应给各个消费者,发送给普通消费者和leader消费者的响应中都包含最终选出的分配策略,响应内容并不完全相同。
- 发送给普通消费者的 JoinGroupResponse 中的members内容为空,而只有leader消费者的 JoinGroupResponse 中的 members 包含有效数据。 members 为数组类型,其中包含各个成员的订阅信息 。
第三阶段(SYNC_GROUP)
- leader消费者根据第二阶段中选举出来的策略来实施具体的分区分配,然后通过GroupCoordinator将方案同步给各个consumer。
- 各个consumer会向GroupCoordinator发送SyncGroupRequest来同步分配方案。GroupCoordinator在收到该请求后会先进行合法性校验,然后将收到的分配方案发给各个消费者。
第四阶段(HEARTBEAT)
- 进入此阶段,consumer即处于正常工作状态
- 正式消费前,consumer还需要确定拉取消息的起始位置:通过OffsetFetchRequest请求获取消费位移
- consumer通过向GroupCoordinator发送心跳来维持与消费组的从属关系,及对partition的所有权关系。
- 如果一个消费者发生崩溃,并停止读取消息,那么 GroupCoordinator 会等待一小段时间,确认这个消费者死亡之后才会触发再均衡。这个一小段时间由
session.timeout.ms参数控制 - 除了被动退出消费组,还可以使用 LeaveGroupRequest 请求主动退出消费组,比如客户端调用了unsubscrible()方法取消对某些主题的订阅
- 如果一个消费者发生崩溃,并停止读取消息,那么 GroupCoordinator 会等待一小段时间,确认这个消费者死亡之后才会触发再均衡。这个一小段时间由
_consumer_offsets剖析
- 一般情况下,集群中第一次有consumer消费消息时,会自动创建主题_consumer_offsets
- 它的副本因子还受
offsets.topic.replication.factor约束。分区数通过offsets.topic.num.partitions设置(默认50)。 - 客户端提交消费位移是使用OffsetCommitRequest实现的
- 删除topic时,会将consumer提交的此topic的offset一并删除
OffsetCommitRequest的消息格式和消费位移对应的内容格式可查阅7.3节
事务
消息传输保障
- 一般消息中间件的消息传输保障有3个层级
- at most once:至多一次。消息可能丢失,但不会重复
- at least once:至少一次。消息不会丢失,但可能重复
- exactly once:恰好一次。每条消息肯定且仅传输一次
- kafka提供的消息传输保障为at least once
- 从0.11.0.0版本开始引入幂等和事务特性来实现EOS(exactly once semantics)
幂等
所谓的幕等,简单地说就是对接口的多次调用所产生的结果和调用一次是一致的。生产者在进行重试的时候有可能会重复写入消息,而使用 Kafka 的幕等性功能之后就可以避免这种情况。
生产者客户端通过设置
enable.idempotence=true(默认false)开启幂等性功能开启幂等时,客户端会对用户显式设定的一些参数进行校验
- retries:必须大于0(默认Integer.MAX_VALUE)
- acks:必须为-1(all,默认为1)
- max.in.flight.requests.per.connection:不能大于5(默认5)
对于每个PID(producer id),消息发送到的每一个partition都有对应的序列号,从0开始,每发送一条就+1,。broker在内存中为每一对 <PID, partition> 维护一个序列号,收到消息时,对比其序列号(SN_new)和内存中的序列号(SN_old)。
生产者客户端和broker端都为每一对<PID, partition>维护一个序列号,生产者客户端每发送一条消息就将该序列号加一,而broker每接受一条消息就加一。
每个新的生产者实例在初始化的时候都会被分配一个PID,这个PID对用户而言是完全透明的。
- 如果SN_new<SN_old+1,说明消息重复写入则丢弃此消息。
- 如果SN_new>SN_old+1,可能有消息丢失,对应producer会抛出异常。
- 只有SN_new刚好比SN_old大1时,才接受此消息。
引入序列号来实现幕等也只是针对每一对<PID,分区>而言的,也就是说Kafka的幂等只能保证单个生产者会话(session)中单分区的幂等.
事务
幂等性并不能跨多个分区运作,而事务可以弥补这个缺陷。事务可以保证对多个分区写入操作的原子性。Kafka引入事务协调器(TransactionCoordinator)负责处理事务。
每一个生产者都会被指派一个特定的 TransactionCoordinator,所有的事务逻辑包括分派 PID 等都是由 TransactionCoordinator 来负责实施的。TransactionCoordinator 会将事务状态持久化到内部主题_transaction_state 中。
生产端
- 为了实现事务,生产端需要开启幂等,并且将
trasactional.id参数设置为非空 - transactionId与PID一一对应,但是transactionId是由用户显式设置,而PID是kafka内部分配。如果使用同一个transactionId开启两个producer,则前一个producer会报错并不再工作。
- KafkaProducer提供了5个事务相关方法:
initTransactions():初始化事务(前提是配置了transactionId)beginTransaction():开启事务sendOffsetsToTransaction():在事务内的位移提交commitTransaction():提交事务abortTransaction():中止事务
消费端
需要配置enable.auto.commit=false
通过配置isolation.level设置事务消息的隔离级别
- read_uncommitted(默认):可消费到未提交的事务
- read_committed:消费端应用看不到尚未提交的事务内的消息(会缓存在KafkaConsumer内部直到事务提交或中止)
KafkaConsumer通过控制消息(ControlBatch)判断事务的提交和中止
事务实现过程
下面以最复杂的 consume-transform-produce 的流程为例来分析 Kafka 事务的实现原理。
consume-transform-produce 模式
在这种模式下消费和生产并存: 应用程序从某个主题中消费消息,然后经过一系列转换后写入另一个主题,消费者可能在提交消费位移的过程中出现问题而导致重复消费,也有可能生产者重复生产消息。
该模式具体代码可查阅7.4.3节。
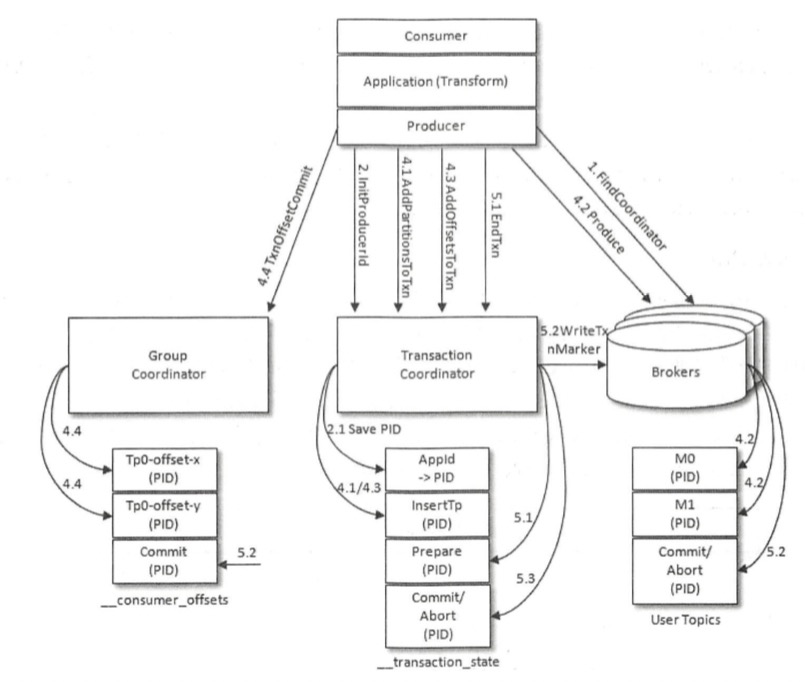
1.查找TransactionCoordinator
- 与查找组协调器类似,根据 transactionalld 的哈希值计算主题_transaction_state中的分区编号,再查找相应的broker节点
2.获取PID
凡是开启了幂等性功能的生产者都必须执行这个操作,而不论是否开启事务
通过向TransactionCoordinator发送InitProducerldRequest请求来实现(若未开启事务,则可发往任意broker)
当TransactionCoordinator第一次收到该请求时,会把请求中的transactionalId和对应的PID以消息的形式保存到主题_transaction_state中,从而持久化transactionalId和PID的关系。
每个新的生产者实例在初始化的时候都会被分配一个 PID,这个PID对用户而言是完全透明的
3.开启事务
- 通过 KafkaProducer的
beginTransaction()方法可以开启一个事务 - 调用该方法后,生产者本地会标记己经开启了一个新的事务 ,只有在生产者发送第一条消息之后 TransactionCoordinator 才会认为该事务己经开启
- 通过 KafkaProducer的
4.Consume-Transform-Produce:事务的处理过程
当生产者给一个新的分区( TopicPartition) 发送数据前, 它需要先向 TransactionCoordinator 发送 AddPartitionsToTxnRequest请求。这个请求会让 TransactionCoordinator 将<transactionld, TopicPartition>的对应关系存储在主题
_transaction_state中。生产者通过 ProduceRequest 请求发送消息(ProducerBatch)到用户自定义主题中
消费者通过 KafkaProducer 的sendOffsetsToTransaction()方法在一个事务里提交位移
- 该方法会向 TransactionCoordinator 节点发送 AddOffsetsToTxnRequest 请求,收到该请求后,协调器会根据groupId推导出
_consumer_offsets中的分区,然后将该分区保存在主题_transaction_state中。(对应图中步骤4.3) - 在处理完 AddOffsetsToTxnRequest 之后,生产者还会发送 TxnOffsetCommitRequest 请求给 GroupCoordinator,从而将本次事务中包含的消费位移信息 offsets 存储到主题
_consumer_offsets中。(对应图中步骤4.4)
- 该方法会向 TransactionCoordinator 节点发送 AddOffsetsToTxnRequest 请求,收到该请求后,协调器会根据groupId推导出
5.提交或中止事务
一旦数据被写入成功,我们就可以调用 KafkaProducer 的
commitTransaction()方法或abortTransaction()方法来结束当前的事务。调用这两种方法后,生产者都会向TransactionCoordinator发送 EndTxnRequest 请求,受到该请求后TransactionCoordinator会执行如下操作:将 PREPARE COMMIT 或 PREPARE_ABORT 消息写入主题
_transaction_state通过 WriteTxnMarkersRequest请求将 COMMIT 或 ABORT 信息写入用户所使用的普通主题和
_consumer_offsets当分区的leader节点收到这个请求之后,会在相应的分区中写入控制消息( ControlBatch)。控制消息用来标识事务的终结,它和普通的消息一样存储在日志文件中
将COMPLETE CO孔仙lfIT或COMPLETE ABORT信息写入内部主题
_transaction_state表明当前事务已经结束,此时可以删除主题
_transaction_state中所有关于该事务的消息。由于主题_transaction_state采用的日志清理策略为日志压缩,所以这里的删除只需将相应的消息设置为墓碑消息即可
