复制
在Redis中,可通过SLAVEOF命令或配置文件中设置slaveof选项,让一个服务器去复制另一个服务器,被复制的为主服务器,对其复制的称为从服务器。
旧版本复制功能的实现
Redis在2.8以前使用旧版本复制,在从服务器断线重连时会遇上低效的情况。
Redis的复制功能分为同步和命令传播俩操作:
- 同步用于把从服务器的数据库状态更新至主服务器的数据库状态。
- 命令传播是在主服务器的数据库状态被修改导致主从数据库状态不一致时,让主从回到一致的过程。
同步
从服务器对主服务器的同步(下文以主从代替),需要向主服务器发送SYNC命令,具体步骤:
- 从向主发送SYNC命令。
- 主接收并执行BGSAVE,后台生成RDB文件,并用一个缓冲区记录现在开始执行的所有写命令。
- BGSAVE执行完毕时,主将RDB文件发给从,从接收并载入,更新数据库状态。
- 主将其记录在缓冲区的所有写命令发给从,从执行写命令。
下图展示了同步的过程:

命令传播
当主发生写操作时,主从同步需要通过命令传播,具体步骤:
- 主将写命令发送给从。
- 从接收并执行相同的写命令。
旧版复制功能的缺陷
旧版复制的缺陷主要体现在断线重连上:
主因为网络原因中断复制,但从通过自动重连连上主,并继续复制主。此时,从发送SYNC命令,希望将断线期间由于对主的写操作造成的主从数据库不一致状态同步回一致状态,但SYNC每次都会重新生成RDB文件,将所有的数据库状态都写到RDB,这就造成了资源的大量浪费。
SYNC命令对性能的损耗比较高主要表现在:
- 主执行BGSAVE生成RDB文件会消耗CPU、内存和磁盘I/O资源。
- 主需要发送RDB,消耗网络资源。
- 从接收并载入RDB,载入期间是阻塞的无法处理命令。
因此,必须是真正有必要时才调用SYNC命令。
新版复制功能的实现
Redis从2.8开始使用PSYNC代替SYNC命令来执行同步操作。
PSYNC有完整重同步和部分重同步的两种模式:
完整重同步用于初次复制的情况,与SYNC命令一样。
部分重同步用于处理断线重连后的情况,重连后,主服务器将断线期间执行的写命令发送给从服务器,从只需接收并执行这些命令。
部分重同步的执行过程:
- 从向主发送PSYNC命令,请求同步数据。
- 主判断后,确认需要执行部分重同步时,返回给从**+COUNTINUE**。
- 主将断线期间的写命令发送给从。
下图展示了部分重同步的过程:

部分重同步的实现
部分重同步基于三个部分实现:
- 主从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 服务器运行ID
复制偏移量
主从都会维护一个复制偏移量,记录存储数据的字节数,当主服务器向从服务器传播N个字节数据时,主的复制偏移量会加N,从接收到之后也会加N。通过偏移量判断数据库状态是否一致。但有一个问题,就是从服务器重连后,需要执行部分还是完整重同步,这时候就需要复制积压缓冲区来帮忙判断。
复制积压缓冲区
复制积压缓冲区由主服务器维护,是固定长度的先进先出队列,默认1M。当入队元素大于队列长度时,最先入队的元素会被弹出。主服务器在命令传播时,不仅将写命令发给从,还会将写命令入队至积压缓冲区。
下图展示了传播的命令发给从并写入缓冲区的过程:
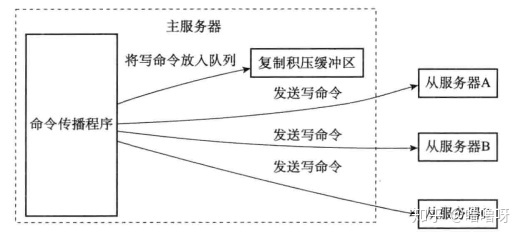
复制积压缓冲区会保存最近写的命令,并为队列中的每个字节记录复制偏移量。

当从服务器重连后,发送PSYNC并将自己的复制偏移量也发送给主服务器,主服务器拿着复制偏移量去复制积压缓冲区找,如果存在则进行部分重同步并给从服务器发送+CONTINUE回复,否则进行完整重同步。
复制积压缓冲区大小应该根据实际场景的两个因素进行调整:
- 断线重连平均时间
- 主服务器平均每秒产生写命令的数据量
一般得将这两个指标相乘后再乘以2,作为复制积压缓冲区的大小,应对大多数断线情况。
服务器运行ID
服务器运行ID决定断线后执行哪种同步方式,主从都有运行ID,是自动生成的40个随机十六进制字符。主从第一次复制时,从服务器会保存主服务器的ID,断线后也会向主服务器发送这个ID,如果不同则进行完整重同步(之前的主服务器由于某些原因连接断开,重新选举的情况);相同则部分重同步。
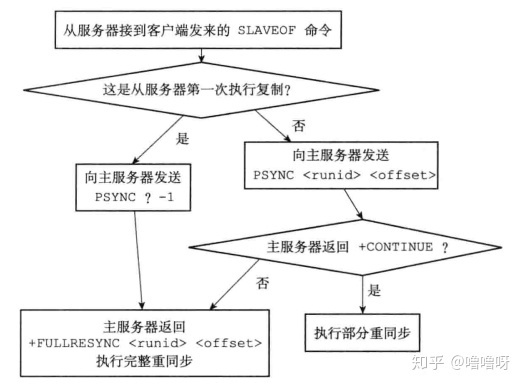
PSYNC命令的实现
PSYNC命令调用方法有两种:
- 从服务器第一次复制时,会发送
PSYNC ? -1命令,请求完整重同步。 - 已经复制过的情况,向主服务器发送
PSYNC <runid> <offset>命令,一个是主服务器运行ID,一个是积压缓冲区的偏移量。
主服务器接收后有3种返回值:
+FULLRESYNC <runid> <offset>:表示执行完整重同步,从服务器会将这两个变量保存。+CONTINUE:执行部分重同步,从服务器等待缺失数据的发送。-ERR:主服务器版本低于2.8,执行完整重同步操作。
下图展示了PSYNC的执行流程:
一次完整的主从复制过程
一次完整的复制过程可以分为设置主服务器的地址和端口、建立套接字连接、发送PING命令、身份验证、发送端口信息、同步、命令传播。
设置主服务器的地址和端口
当客户端向服务器发送SLAVEOF命令时,从服务器会将主服务器的ip和端口都保存后发送OK。这是一个异步命令,所以复制工作在回复OK后再执行。
建立套接字连接
从服务器此时创建连接主服务器的套接字,如果套接字能成功连接,从服务器会给它关联一个处理复制工作的文件事件处理器(负责接收RDB,传播的命令等)。主从成功连接后,主服务器会创建从服务器的客户端状态。
发送PING命令
从服务器在套接字连接后做的第一个工作就是发送PING命令,检查套接字读写状态是否正常;主服务器能否正常处理命令请求。而主服务器会根据网络状态、能够处理给出对应回复。一旦回复超时或返回错误,从服务器就会断开并重连主服务器。
身份验证
检查从服务器是否设置masterauth,如果设置则进行身份验证。
发送端口信息
身份验证后,从服务器向主服务器发送自己监听的端口号,主服务器保存这个端口号。
同步
从服务器发送PSYNC命令,主从互相成为对方的客户端,都能够执行命令并回复,执行同步操作,看是完整重同步还是部分重同步。
命令传播
完成同步后,进入该阶段,主服务器将写命令发送给从服务器,从服务器接收并执行。
心跳检测
在命令传播阶段,从服务器默认1秒一次发送REPLCONF ACK <replication_offset>命令给主服务器,replication_offset是复制偏移量。这么做有3个作用:
- 检测主从网络状态
- 辅助实现min-slave选项
- 检测命令丢失
检测主从网络状态
下面分别说这三个作用。检测网络连接很好理解,如果主服务器超过一秒没收到从服务器的REPLCONF ACK则表示连接有问题。
辅助实现min-slave选项
Redis的min-slaves-to-write和min-slaves-max-lag可防止主服务器在不安全的情况下执行写命令。如果设置如下:
1 | min-slaves-to-write 3 |
表示从服务器数量少于3或3个从服务器延迟大于等于10s时,主服务器拒绝写命令。
检测命令丢失
通过发送的偏移量,主服务器会判断命令是否有丢失,如果丢失,就从积压缓冲区里找到并补发。
注:Redis2.8之前版本并不会注意到丢失数据,所以保持主从数据一致性最好使用以上版本。
Sentinel机制
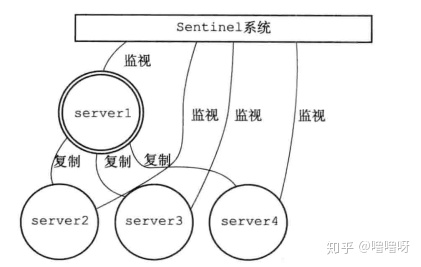
Sentinel(哨兵)是Redis的高可用性的解决方案,由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器以及属下的所有从服务器。当主服务器下线时,自动将下线的某个主服务器属下的某个从服务器升级为新的主服务器。从而实现故障转移,当原来的主服务器重新上线时,会被降级为从服务器。
下面展示了哨兵监视主从的状态:
下面主要讲解Sentinel系统对主服务器执行故障转移的整个过程。
启动并初始化Sentinel
启动Sentinel有两种方式:
redis-sentinel /path/to/your/sentinel.confredis-server /path/to/your/sentinel.conf --sentinel
俩命令效果相同,启动时需要执行以下步骤:
- 初始化服务器。
- 将普通Redis服务器使用的代码替换成Sentinel专用代码。
- 初始化Sentinel状态。
- 根据配置文件,初始化Sentinel的监视主服务器列表。
- 创建连向主服务器的网络连接。
接下来对这些步骤进行详细说明。
初始化服务器
Sentinel实际上是一个特殊的Redis服务器,所以很多地方和Redis服务器的初始化有些类似。只不过少了RDB或AOF文件的载入等操作。
使用Sentinel专用代码
将加载的常量,命令表(决定了Sentinel可以执行哪些命令)等替换为Sentinel专用的。
初始化Sentinel状态
初始化一个sentinel.c/sentinelState结构,记录Sentinel的状态,保存了服务器中所有与Sentinel相关的状态:
1 | struct sentinelState{ |
初始化master属性
masters字典的值是一个指向sentine1RedisInstance结构的指针,而一个sentine1RedisInstance实例包括主服务器、从服务器或另一个Sentinel。实例结构如下,了解一下,故障转移的可以先不关注:
1 | typedef struct sentinelRedisInstance { |
创建连向主服务器的网络连接
Sentinel会为监视的主服务器创建两个异步网络连接:
- 命令连接:专用于向主服务器发送命令,接收命令回复。
- 订阅连接:专用于订阅主服务器
__sentinel__:hello频道。(由于Redis的发布订阅消息不会保存,客户端断线就会丢失,为了不丢失,必须使用专门的频道连接)
获取主从服务器信息
Sentinel默认10秒一次通过命令连接向被监视的主服务器发送INFO命令,获取主服务器信息。
主要获取主服务器本身信息(如服务器运行ID),下属从服务器信息(如ip,port,offset)。对主服务器实例和从服务器实例的相应属性进行更新,如果没有某个从服务器的信息就会创建一个实例结构,放到主服务器实例的slaves字典中,键为ip+端口,值为sentinelRedisInstance。
除了创建新实例,还会创建连接到从服务器的命令连接和订阅连接。在创建命令连接后,Sentinel默认10秒一次通过命令连接向从服务器并发送INFO命令,获取从服务器信息(运行ID,角色,ip和端口,优先级等)。之后根据这些信息对从服务器的实例结构进行更新。
向主服务器和从服务器发送消息
sentinel默认以两秒一次,通过命令连接向服务器的__sentinel__:hello频道发送消息,命令:
1 | PUBLISH __sentinel__:hello "<s_ip>,<s_port>,<s_runid>,<s_epoch>,<m_name>,<m_ip>,<m_port>,<m_epoch>" |
参数包含sentinel本身(s_...)和主服务器(m_...)的运行ID,ip,端口号,配置纪元等参数。
接收来自主服务器和从服务器的频道信息
Sentinel与一个主服务器或从服务器建立订阅连接后,会发送SUBSCRIBE _sentinel_:hello命令。
也就是Sentinel通过命令连接发送信息到频道,又通过订阅连接接收频道中的信息。一个Sentinel发的信息也会被其他Sentinel接收,根据信息记录的Sentinel运行id和接收信息的Sentinel运行id是否相同,来决定是否处理这条消息。通过这种透明的沟通机制,Sentinel可以对各自监听的服务器信息进行更新。
更新sentinels字典
根据接收而来的消息,Sentinel会更新实例结构中sentinels字典保存的所有Sentinel实例的信息。键为Sentinel的ip+端口,值为某个Sentinel的实例。消息接收者会检查发送消息的Sentinel(源sentinel)结构是否在sentinels字典,若存在则更新,没有则创建实例,和自己相同的sentinel不会被放入。
1 | typedef struct sentinelRedisInstance{ |
通过这种发布订阅的方式,Sentinel不需要各自发信息告诉对方,而是监视同一个主服务器的多个Sentinel自动发现对方。
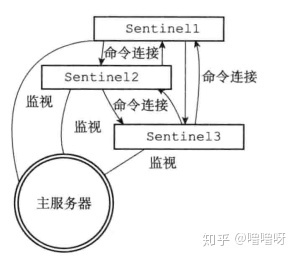
创建连向其他Sentinel的命令连接
sentinel也会为对方互相创建命令连接,最终监视同一主服务器的多个sentinel会形成一个网络。但他们互相之间不会创建订阅连接,因为他们通过主或从服务器发来的频道来发现未知的sentinel。
下图展示了多个sentinel通过命令连接形成网络:
检测主观下线状态
Sentinel默认每秒与创建命令连接的实例(主服务器,从服务器,其他sentinel)发送PING命令,通过回复判断是否在线。如果实例返回除了+PONG,-LOADING,-MASTERRDOWN之外的回复或未及时回复,就认为是无效回复。
根据配置文件的down-after-milliseconds指定的主观下线所需时长内是否一直无效回复,来判断实例是否已经主观下线。下线了就将实例的的flags标识属性打开SRI_S_DOWN标识。由于每个Sentinel中的主观下线时间配置都可以不同,所有有可能某个Sentinel判断主观下线时,另一个Sentinel认为在线状态。
检查客观下线状态
当Sentinel判断主服务器为主观下线时,还会向其他Sentinel询问,得到足量数量的已下线判断后,就会判定服务器为客观下线,并执行故障转移。
发送sentinel is-master-down-by-addr命令
Sentinel使用:SENTINEL is-master-down-by-addr <ip> <port> <current. epoch> <runid>命令询问其他Sentinel是否同意主服务器下线。这些参数分别是Sentinel的ip,端口,配置纪元和运行id。
接收sentinel is-master-down-by-addr命令
其他哨兵节点接收并返回三个参数的Multi Bulk回复:
:是对主服务器的检查结果,1表示已下线;0表示未下线。 :如果是*,表示该命令用于检测服务器状态;如果是Sentinel的运行id用于选举领头Sentinel。 :选举计数器,用于选举领头sentinel。
接收sentinel is-master-down-by-addr命令的回复
统计其他Sentinel同意主服务器已下线数量,当数量超过配置值(quorum参数)时,sentinel会将主服务器实例的flags属性的SRI_O_DOWN属性打开,表示已进入客观下线状态。
1 | typedef struct sentinelRedisInstance { |
选举领头Sentinel
当主服务器被判断为客观下线时,sentinel会协商选举领头sentinel,并由领头sentinel对下线主服务器执行故障转移操作。
当SENTINEL is-master-down-by-addr命令已经确认主服务器客观下线时,Sentinel还会再发送带有选举性质的该命令,并且带上自己的运行ID。如果接收命令的Sentinel还没设置局部领头时,就会将这个运行ID作为自己的Multi Bulk回复参数。根据回复参数来判断多少sentinel将自己设置为局部领头。可能根据网络延迟,有的Sentinel命令比其他Sentinel都先到达,并且胜出(必须有半数以上的票),那么就由它负责故障转移。
若一次选举没有产生领头Sentinel,一段时间后再次选举,直到选出为止。
故障转移
故障转移包括3步:
- 在已下线的主服务器属下从服务器里选出一个将其转为主服务器。
- 让其他从服务器都复制新主服务器。
- 当原来的主服务器再次上线时,让他成为新主服务器的从服务器。
选出新主服务器
如何选新的主服务器?Sentinel会将所有从服务器放入列表,一项一项过滤:
- 删除处于下线或断线状态的从服务器。
- 删除最近5秒没有回复过领头
sentinel INFO命令的从服务器。 - 删除与已下线主服务器段开时间超过
down-after-milliseconds*10毫秒的从服务器。
然后根据优先级排序,相同则选偏移量最大的,再相同则选运行ID最小的。
选出来之后,对这个从服务器发送SLAVEOF no one命令,然后以每秒一次的频率向它发送INFO命令,观察返回的role属性如果变成master,就表示顺利升级为主服务器了。
修改从服务器的复制目标
向所有其他从服务器发送SLAVEOF命令,让他们都去复制新的主服务器。
将旧的主服务器变为从服务器
当原来的主服务器上线时,Sentinel就会向它发送SLAVEOF命令,让他成为新主服务器的从服务器。
cluster集群
集群是Redis提供的分布式数据库方案,通过分片来进行数据共享并提供复制和故障转移的功能。主要对集群的节点,槽指派,命令执行,重新分片,转向,故障转移,消息进行介绍。
节点
集群由多个节点组成,通过CLUSTER MEET <ip> <port>可以将节点连接起来。这个命令主要是将目标节点加入到当前Redis所在的集群中。下面从启动节点,集群相关数据结构,命令实现来介绍节点内容。
启动节点
Redis服务器在启动时会根据cluster-enable配置是否为yes来决定是否开启集群模式。
集群中的节点除了使用redisServer,redisClient之外,还用cluster.h/clusterNode结构、cluster.h/clusterLink结构、cluster.h/clusterState结构来保存集群数据。
集群数据结构
集群的每个节点都会用clusterNode来保存:
1 | struct clusterNode { |
link属性保存了连接节点所需的有关信息:
1 | typedef struct clusterLink { |
每个节点都保存一个集群状态,记录在当前节点下:
1 | typedef struct clusterState { |
CLUSTER MEET命令的实现
通过向节点A发送CLUSTER MEET命令,让目标节点B加入集群,进行握手,执行过程如下:
- 客户端发送该命令给节点A,节点A会创建一个节点B的clusterNode结构,添加到clusterState.nodes中。
- 解析IP地址和端口号,向节点B发送MEET消息(最后一节会讲消息)。
- 同理,节点B收到后,会为A创建clusterNode结构并添加到nodes。
- 节点B向A发送PONG消息。
- 节点A收到后向B发送一条PING消息。
- 节点B收到后直到A成功感知到B,握手完成。
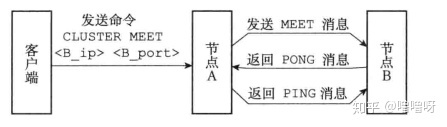
之后,节点A将节点B的信息通过Gossip协议(最后一节消息中将提到)传播给集群中的其他节点。
槽指派
Redis通过分片方式保存键值对,集群的整个数据库被分为16384个槽(slot),数据库的每个键都属于某一个槽,每个节点可处理0~16384个槽。当集群中的每个槽都归某个节点管理,集群处于上线状态;但凡有一个没人管,集群处于下线状态。
发送CLUSTER ADDSLOTS <slot> [slot...]命令,可以将槽委派给某个节点负责。下面介绍槽的实现。
记录节点的槽指派信息
clusterNode有slots和numslot属性记录了节点负责处理的槽:
1 | struct clusterNode{ |
比如该节点负责0~7的槽,存储结构如下:

通过这种设计,检查某节点是否负责处理某个槽或者让节点负责某个槽的操作的时间复杂度都为**O(1)**。
传播节点的槽指派信息
节点除了将自己负责的槽记录在clusterNode.slots中,还会将这个数组通过消息发送给其他节点,让他们都知道自己负责什么槽。其他节点接收消息后,会对clusterStaste.nodes字典中对应的clusterNode.slots数据进行更新。
记录集群所有槽的指派信息
clusterState会维护集群中每个节点管理槽的情况:
1 | typedef struct clusterState{ |
如果slot[i]指向空,说明该槽没有被节点管理;如果指向具体某个clusterNode,说明该槽由这个节点管理。
总结一下,clusterState.slots数组记录集群中所有槽的信息;clusterNode.slots数组记录当前节点负责槽的信息。前者方便知道某个槽指派给谁,后者方便知道某个槽是否指派给自己,或者发送自己槽的指派信息。(因为被指派后,还需要向其他节点发送消息告知)。
CLUSTER ADDSLOTS命令的实现
这个命令的执行其实就是把上面讲的几小节知识给串起来。主要是用来指派槽给节点负责的,接收该命令后,首先会遍历所有传入的槽(命令入参)检查其是否都是未指派的,如果有一个被指派了就报错。如果都未指派,将这些槽委派给当前节点,更新clusterState.slots数组指向当前节点的clusterNode;然后将clusterNode.slots数组中对应的索引二进制位设置为1。最后,发送消息告诉集群中其他节点,自己负责这些槽。
在集群中执行命令
当客户端对节点发送与数据库键有关的命令时,接收命令的节点会计算属于哪个槽,检查这个槽是否指派给自己(根据key的CRC-16校验和16383做与操作来确定槽号i,再根据clusterState.slots[i]是否指向当前节点的clusterNode判断是否自己负责的)。
如果不是指派给自己的,就(找负责该槽的节点的ip和端口,指引客户端转向它)向客户端返回MOVED错误,引导客户端指向正确的节点并再次发送命令。
注:通过
CLUSTER KEYSLOT <key>可查看某个key对应的槽号。
MOVED错误
MOVED错误格式为:MOVED <slot> <ip>:<port>
在集群模式下,会被隐藏,客户端会进行自动转向并重发命令。节点的转向其实就是换对应套接字来发送命令。下面演示了对7000端口的节点操作键命令并被引导转向到真正存储该键的服务器(7001端口)的过程:
1 | 127.0.0.1: 7000> SET msg "hello" |
节点数据库的实现
节点对数据的存储和单机Redis的实现是一样的,只不过节点只能使用0号库。还需要维护一个slots_to_keys跳跃表关联槽号和键。分值是槽号,成员就是键。当节点往数据库添加新键时,节点就会在slots_to_keys中进行关联,反之则删除关联。
1 | typedef struct clusterState{ |
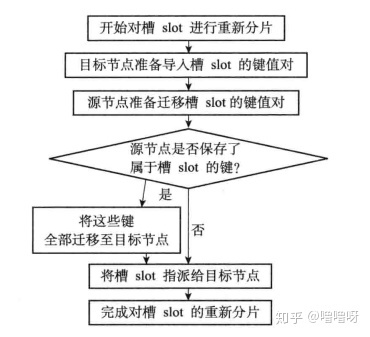
重新分片
Redis集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点被移动到目标节点。
重新分片通过集群管理软件redis-trib执行,步骤如下:
- redis-trib对目标节点发送
CLUSTER SETSLOT <slot> IMPORTING <source_id>命令,让目标节点准备好,要导入键值对了。 - redis-trib对源节点发送
CLUSTER SETSLOT <slot> MIGRATING <target_id>命令,让源节点准备好,要转移键值对了。 - redis-trib 向源节点发送
CLUSTER GETKEYSINSLOT <slot> <count>命令, 获得最多count个属于槽slot的键值对的键名( key name ),这实际上就是个批量分片的意思。 - 对于步骤3获得的每个键名,redis-trib都向源节点发送一个
MIGRATE <target_ip> <target_ port> <key_name> 0 <timeout>命令,将被选中的键原子地从源节点迁移至目标节点。 - 重复执行步骤3和步骤4,直到源节点保存的所有属于槽slot的键值对都被迁移至目标节点。
- redis-trib向集群中的任意一个节点发送
CLUSTER SETSLOT <slot> NODE <target_ id>命令,将槽slot指派给目标节点这个信息,通过消息发送至整个集群,让所有节点感知。
整体迁移的流程图:
ASK错误
当客户端向源节点发送与数据库键相关的命令,并且该键恰好属于被迁移的槽时,源节点会先查自己有没有,有就返回;没有则返回ASK错误,指引客户端向正在导入该槽的目标节点发送命令。这个命令和MOVED类似,不会直接打印错误。比如端口7000是源节点,”love”键的槽(16198槽)正在被迁移到7001就会这样:
1 | 127.0.0.1: 7000> GET "love" |
CLUSTER SETSLOT IMPORTING的实现
clusterState.importing_slots_from数组记录当前节点正在从其他节点导入的槽:
1 | typedef struct clusterState{ |
一般情况下指向空,当执行CLUSTER SETSLOT <i> IMPORTING <source_id>时,会将目标节点(当前节点)clusterState.importing_slots_from[i]设置为source_id所代表节点的clusterNode。
CLUSTER SETSLOT MIGRATING的实现
clusterState结构的migrating_slot_to数组记录了当前节点正在迁移至其他节点的槽:
1 | typedef struct clusterState{ |
一般情况下指向空,当执行CLUSTER SETSLOT <i> MIGRATING <target_id>时,会将源节点clusterState.migrating_slots_to[i]设置为target_id所代表节点的clusterNode。
ASK错误
如果节点收到一个关于键key的命令请求,并且键key所属的槽正好指派给了该节点,那么该节点会尝试在自己的数据库里查找键key,找到则返回,如果没找到则检查clusterState.migrating_slots_to[i],是否正在迁移,如果正在迁移,就向客户端返回ASK错误,引导其去导入槽的节点查询。
客户端接收到ASK错误后,根据IP和端口,转向目标节点,然后先向目标节点发送ASKING命令,再重新发送要执行的命令。
ASKING命令
这个命令的唯一作用就是打开发送该命令客户端的REDIS_ASKING标识。有了这个标识后,节点会为正在导入的键执行命令。这个标识是一次性的,如果再对刚才的key执行相关操作,该节点会返回MOVED错误(因为重分片未结束,它不是负责该槽的节点)。下面表示相关判断过程:
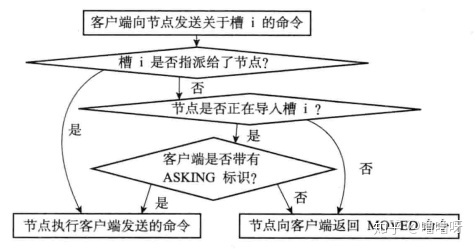
ASK错误与MOVED错误的区别
这两个错误都会导致客户端转向:
- MOVED错误代表槽的负责权已经从一个节点到了另一个节点。
- ASK错误只是两个节点再迁移槽过程中使用的临时措施。
复制与故障转移
Redis集群中的节点分主节点和从节点,主节点用于处理槽,从节点用于复制某个主节点(相当于备份,不处理读请求),并在被复制节点下线时,代替下线主节点继续处理命令请求。
接下来介绍节点的复制方法,检测节点是否下线方法及对下线节点故障转移方法。
设置从节点
向节点发送命令CLUSTER REPLICATE <node_id>可以让接收命令的节点成为指定节点的从节点并对主节点开始复制。主要过程是:
- 接收命令节点在
clusterState.node字典中找到node_id对应节点的clusterNode,然后将clusterState.myself.slaveof指向这个节点。 - 修改
clusterState.myself.flags属性,关闭REDIS_NODE_MASTER标识,打开REDIS_NODE_SLAVE标识,标识该节点成为从节点。 - 调用复制代码,对主节点复制。
当节点成为从节点并开始复制时,这个信息会通过消息发送给集群中其他节点。
故障检测
集群中每个节点都会定期向其他节点发送PING消息,如果没有在规定时间返回PONG消息,就会被标记位疑似下线。集群中各个节点会互相发送消息来交换各个节点的状态,当一个主节点A通过消息得知主节点B认为主节点C进入疑似下线状态,A会将B的下线报告添加到clusterNode.fail_reports链表中。
链表中每个元素都由clusterNodeFailReport组成:
1 | struct clusterNodeFailReport{ |
在一个集群中,半数以上负责处理槽的主节点将某个主节点报告为疑似下线后,这个主节点将被标记为已下线。并向集群广播一条关于该主节点FAIL的消息,所有收到消息的节点都会将其标记为已下线。
故障转移
当一个从发现主节点下线后,开始故障转移。具体步骤:
- 下线的主节点的所有从节点里面,会有一个从节点被选中。
- 被选中的从节点会执行
SLAVEOF no one命令,成为新的主节点。 - 新的主节点会撤销对已下线主节点的槽指派,并将这些槽指派给自己。
- 新的主节点向集群广播一条PONG消息,让其他节点立即知道新的主节点。
- 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
选举新的主节点
集群选举新主节点的具体过程:
- 通过集群的配置纪元确定是哪一次选举,它是一个自增计数器,初始值为0。
- 当集群里的某个节点开始一次故障转移操作时,集群配置纪元的值会被加一。
- 集群里每个负责处理槽的主节点都有一次投票的机会,第一个向主节点要求投票的从节点将获得主节点的投票。
- 当从节点发现自己正在复制的主节点进入已下线状态时,从节点会向集群广播一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有收到这条消息并且具有投票权的主节点向这个从节点投票。 - 如果一个主节点具有投票权(它正在负责处理槽),并且这个主节点尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点。 - 每个参与选举的从节点都会接收
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,并根据自己收到消息的条数来统计自己获得多少主节点的支持。 - 如果集群里有N个具有投票权的主节点,那么当一个从节点收集到大于等于N/2+1 支持票时,这个从节点就会当选为新的主节点。
- 配置纪元确定每个具有投票权的主节点只能投一次,所以如果有N个主节点进行投票,那么具有大于等于N/2+1张支持票的从节点只会有一个,这确保了新的主节点只会有一个。
- 如果在一个配置纪元里没有从节点得到足够的票,那么集群进入一个新的配置纪元,并再次进行选举,直到选出新的主节点为止。
消息
集群中节点主要通过发送消息来传递信息,主要有5种:
- MEET消息:发送者接收到客户端的CLUSTER MEET消息时,发送者向接收者发送MEET消息,请求加入发送者所在集群。
- PING消息:集群每个节点每隔一秒从已知节点随机选出5个节点,然后对最长时间没发PING消息的节点进行发送。除此之外,如果最后一次收到某节点的PONG消息的时间,超过配置的
cluster-node-timeout选项的一半时,也会发送PING消息。 - PONG消息:应答MEET或PING消息。还可以通过PONG,告诉其他节点,刷新该节点的相关信息。
- FAIL消息:当某个主节点判断另一个主节点已经进入FAIL状态时,当前主节点会向集群广播一条关于已下线节点的FAIL消息。
- PUBLISH消息:当节点接收到PUBLISH命令时,执行这个命令,并向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会执行相同的PUBLISH命令。
一条消息由消息头和消息正文组成。
消息头
记录信息发送者的一些信息。比如发送者的当前纪元,发送者名字,发送者的槽指派信息等。接收者可根据发送者的信息来更新发送者的状态。消息头是一个cluster.h/clusterMsg:
1 | typedef struct{ |
其中消息正文是一个cluster.h/clusterMsgData结构:
1 | union clusterMsgData{ |
MEET、PING、PONG消息的实现
集群中的各个节点通过Gossip协议来交换各自关于不同节点的状态信息,Gossip协议由MEET、PING、PONG这三种消息实现,他们的的正文就是上面的ping结构体。
因为共用消息正文,所以需要消息头的type属性来区分。每次发送这类消息时,发送者都从已知节点中随机选择两个节点保存到clusterMsgDataGossip,因此正文包含两个clusterMsgDataGossip结构:
1 | typedef struct ( |
消息接收者会根据clusterMsgDataGossip包含的节点,看是否为第一次接触,如果是的话,需要进行一次握手,记录节点信息;如果已经存在于已知节点中,则对相关节点信息更新。
FAIL消息的实现
在集群节点较多的情况下,单纯使用Gossip会带来一些延迟,FAIL消息需要所有节点立刻知道某个主节点下线了,从而尽快判断是否需要标记为下线或故障转移。消息正文是一个cluster.h/clusterMsgDatafail结构:
1 | typedef struct{ |
因为名字都是集群内唯一的,所以可以这么保存。
PUBLISH消息的实现
当集群的某个节点发送PUBLISH <channel> <message>时,会引发集群中所有节点都向channel发送消息。消息正文是一个cluster.h/clusterMsgDataPublish结构:
1 | typedef struct { |
bulk_data保存消息的channel和message参数。具体是根据对应参数长度识别的。
总结
复制章节主要讲述主从复制功能,通过复制偏移量判断是否数据不一致,然后根据复制积压缓冲区和运行id判断执行完全重同步还是部分重同步,从而解决断线重连后的系统资源损耗问题。命令传播的心跳检测1秒一次,由从服务器发送,保障网络通常,防止主服务器在不安全的情况下执行写命令。
哨兵章节主要讲述哨兵的数据结构,命令实现,选举,故障转移等操作。Redis的哨兵集群模式是高可用的解决方案,默认每10秒一次向主从服务器发送INFO命令更新信息,主服务器下线或故障转移时会1秒一次。Sentinel每秒一次与创建命令连接的实例发送PING命令,根据配置的时间内未得到回复就标记为主观下线。然后询问其他Sentinel,得到足量下线判断后会标记为客观下线。发现客观下线的哨兵就会发起选举哨兵领头,根据规则(Raft算法),一半以上支持则成功担任并负责故障转移工作。根据配置规则向过滤不在线的从服务器,然后按优先级,偏移量,运行id排序选择主服务器并让从服务器都复制它。
集群章节主要讲述Redis的cluster集群模式下的集群数据结构,实现原理,选举,故障转移等操作。这种集群模式提供了分布式的数据存储。每个节点都维护了集群状态,各个节点状态信息还有槽指派信息。集群将数据分区,按槽存储,key的CRC-16的校验码决定了存放于哪个槽,每个主节点都指派不同的槽。当对某个节点执行key的相关命令时,会先判断是否归这个槽负责,如果不是则产生MOVED错误引导客户端指向正确的节点。如果归这个槽负责并且key在重分片,就会产生ASK错误,引导客户端指向目标节点。发送ASKING后,才能执行相关读写命令。这种集群模式,主节点负责读写,从节点复制,作为一个备份。
当从节点发现主节点下线,就进行故障转移,通过配置纪元选举出主节点,将原先槽指派给它,并且广播一条PONG消息,让其他节点知道。节点之间传递信息依赖消息,有MEET、PING、PONG、FAIL、PUBLISH消息。
