Recycler 示例代码
1 | public class UserCache { |
控制台的输出结果如下:
1 | hello |
代码示例中定义了对象池实例 userRecycler,其中实现了 newObject() 方法,如果对象池没有可用的对象,会调用该方法新建对象。此外需要创建 Recycler.Handle 对象与 User 对象进行绑定,这样我们就可以通过userRecycler.get() 从对象池中获取 User 对象,如果对象不再使用,通过调用 User 类实现的recycle()方法即可完成回收对象到对象池。
Recycler 设计思想
对象池与内存池的都是为了提高 Netty 的并发处理能力,我们知道 Java 中频繁地创建和销毁对象的开销是很大的,所以很多人会将一些通用对象缓存起来,当需要某个对象时,优先从对象池中获取对象实例。通过重用对象,不仅避免频繁地创建和销毁所带来的性能损耗,而且对 JVM GC 是友好的,这就是对象池的作用。
在Recycler中一共有四个核心组件:Stack、WeakOrderQueue、Link、DefaultHandle,接下来我们逐一进行介绍。
内部结构
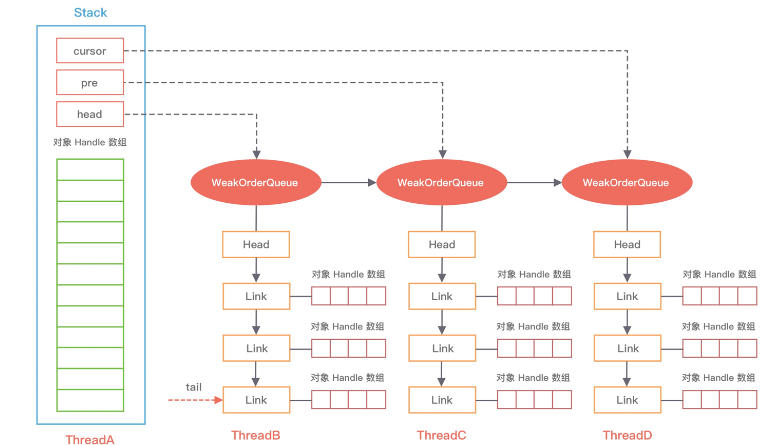
Stack
Stack 是整个对象池的顶层数据结构,描述了整个对象池的构造,用于存储当前本线程回收的对象。在多线程的场景下,Netty 为了避免锁竞争问题,每个线程都会持有各自的对象池,内部通过 FastThreadLocal 来实现每个线程的私有化(关于 FastThreadLocal 的内容可参考Netty的FastThreadLocal)。
先看下 Stack 的数据结构,其源码如下:
1 | static final class Stack<T> { |
对应上面 Recycler 的内部结构图,Stack 包括用于存储缓存数据的 DefaultHandle 数组,以及维护了 WeakOrderQueue 链表中的三个重要节点。
除此之外,Stack 其他的重要属性在源码中已经全部以注释的形式标出,大部分已经都非常清楚,其中 availableSharedCapacity 是比较难理解的,每个 Stack 会维护一个 WeakOrderQueue 的链表,每个 WeakOrderQueue 节点会保存非当前线程的其他线程所回收的对象,例如图中 ThreadA 表示当前线程,WeakOrderQueue 的链表存储着 ThreadB、ThreadC 等其他线程回收的对象。availableSharedCapacity 的初始化方式为 new AtomicInteger(max(maxCapacity / maxSharedCapacityFactor, LINK_CAPACITY)),默认大小为 16K,其他线程在回收对象时,最多可以回收 ThreadA 创建的对象个数不能超过 availableSharedCapacity。
还有一个疑问就是既然 Stack 是每个线程私有的,为什么 availableSharedCapacity 还需要用 AtomicInteger 呢?因为 ThreadB、ThreadC 等多个线程可能都会创建 ThreadA 的 WeakOrderQueue,存在同时操作 availableSharedCapacity 的情况。
WeakOrderQueue
WeakOrderQueue 用于存储其他线程回收到的当前线程所分配的对象,并且在合适的时机,Stack 会从这些 WeakOrderQueue 中收割对象。例如,当ThreadB 回收到 ThreadA 所分配的对象时,就会将该对象放到 ThreadA 的 WeakOrderQueue 当中。
Link
每个 WeakOrderQueue 中都包含一个 Link 链表,回收的对象都会被存在 Link 链表中的节点上,每个 Link 节点默认存储 16 个对象,当一个 Link 节点存储满了会创建新的 Link 节点放入链表尾部。
DefaultHandle
DefaultHandle 实例中保存了实际回收的对象,Stack 和 WeakOrderQueue 都使用 DefaultHandle 存储回收的对象。在 Stack 中包含一个 elements 数组,该数组保存的是 DefaultHandle 实例。WeakOrderQueue 中每个 Link 节点所存储的 16 个对象也是使用 DefaultHandle 表示的。
Recycler 获取对象原理
从代码示例中可以看出,从对象池中获取对象的入口是在 Recycler#get() 方法,直接定位到源码:
1 | public final T get() { |
Recycler#get() 方法的逻辑非常清晰,首先通过 FastThreadLocal 获取当前线程的唯一栈缓存 Stack,然后尝试从栈顶弹出 DefaultHandle 对象实例,若栈中存在实例则直接返回,否则会调用 newObject 生成一个新的对象,完成 handle 与用户对象和 Stack 的绑定。
那么 Stack 是如何从 elements 数组中弹出 DefaultHandle 对象实例的呢?只是从 elements 数组中取出一个实例吗?我们一起跟进下 stack.pop() 的源码:
1 | DefaultHandle<T> pop() { |
如果 Stack 的 elements 数组中有可用的对象实例,直接将对象实例弹出;如果 elements 数组中没有可用的对象实例,会调用 scavenge 方法,scavenge 的作用是从其他线程回收的对象实例中转移一些到 elements 数组当中,也就是说,它会想办法从 WeakOrderQueue 链表中迁移部分对象实例。
每个 Stack 会有一个 WeakOrderQueue 链表,每个 WeakOrderQueue 节点都存储着相应异线程回收的对象,那么以什么样的策略从 WeakOrderQueue 链表中迁移对象实例呢?继续跟进 scavenge 的源码:
1 | boolean scavenge() { |
scavenge 的源码中首先会从 cursor 指针指向的 WeakOrderQueue 节点回收部分对象到 Stack 的 elements 数组中,如果没有回收到数据就会将 cursor 指针移到下一个 WeakOrderQueue,重复执行以上过程直至回到到对象实例为止。具体的流程可以结合下图来理解。
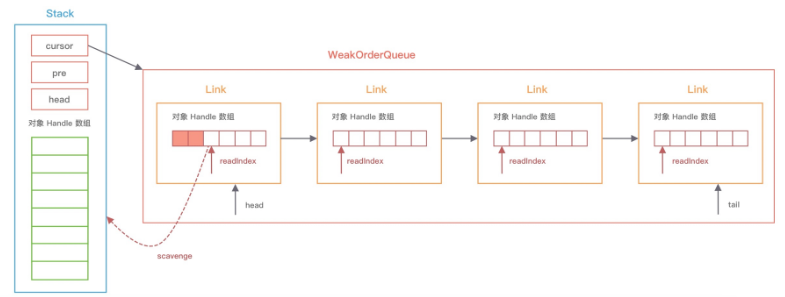
此外,每次移动 cursor 时,都会检查 WeakOrderQueue 对应的线程是否已经退出了,如果线程已经退出,那么线程中的对象实例都会被回收,然后将 WeakOrderQueue 节点从链表中移除。
那每次 Stack 从 WeakOrderQueue 链表会回收多少数据呢?我们依然结合上图讲解,每个 WeakOrderQueue 中都包含一个 Link 链表,Netty 每次会回收其中的一个 Link 节点所存储的对象(不一定有16个)。从图中可以看出,Link 内部会包含一个读指针 readIndex,每个 Link 节点默认存储 16 个对象,读指针到链表尾部就是可以用于回收的对象实例,每次回收对象时,readIndex 都会从上一次记录的位置开始回收。
在回收对象实例之前,Netty 会计算出可回收对象的数量(transfer 方法中),加上 Stack 中已有的对象数量后,如果超过 Stack 的当前容量且小于 Stack 的最大容量,会对 Stack 进行扩容。为了防止回收对象太多导致 Stack 的容量激增,在每次回收时 Netty 会调用 dropHandle 方法控制回收频率,具体源码如下:
1 | boolean dropHandle(DefaultHandle<?> handle) { |
dropHandle 方法中主要靠 hasBeenRecycled 和 handleRecycleCount 两个变量控制回收的频率,会从每 8 个未被收回的对象中选取一个进行回收,其他的都被丢弃掉。
到此为止,从 Recycler 中获取对象的主流程已经讲完了,简单总结为两点:
- 当 Stack 中 elements 有数据时,直接从栈顶弹出。
- 当 Stack 中 elements 没有数据时,尝试从 WeakOrderQueue 中回收一个 Link 包含的对象实例到 Stack 中,然后从栈顶弹出。
Recycler 回收对象原理
同样从上文代码示例中定位到对象回收的源码入口为 DefaultHandle#recycle()。
1 | public void recycle(Object object) { |
在回收对象时,会向 Stack 中 push 对象,push 会分为同线程回收和异线程回收两种情况,分别对应 pushNow 和 pushLater 两个方法,我们逐一进行分析。
同线程对象回收
如果是当前线程回收自己分配的对象时,会调用 Stack#pushNow 方法:
1 | private void pushNow(DefaultHandle<?> item) { |
同线程回收对象的逻辑非常简单,就是直接向 Stack 的 elements 数组中添加数据,对象会被存放在栈顶指针指向的位置。如果超过了 Stack 的最大容量,那么对象会被直接丢弃,同样这里使用了 dropHandle 方法控制对象的回收速率,每 8 个对象会有一个被回收到 Stack 中。
异线程对象回收
异线程回收对象时,会调用 pushLater 方法。我们合理得猜测,异线程并不会将对象添加到 Stack 中,而是会与 WeakOrderQueue 直接打交道,下面是 Stack#pushLater 的源码:
1 | private void pushLater(DefaultHandle<?> item, Thread thread) { |
pushLater 的实现过程可以总结为两个步骤:获取 WeakOrderQueue,添加对象到 WeakOrderQueue 中。
- 首先看下如何获取 WeakOrderQueue 对象。通过 FastThreadLocal 取出当前对象的 DELAYED_RECYCLED 缓存,DELAYED_RECYCLED 存放着当前线程帮助其他线程回收的对象对应的 Stack 以及 WeakOrderQueue 之间的映射关系。例如,假如 item 是 ThreadA 分配的对象,当前线程是 ThreadB,此时 ThreadB 帮助 ThreadA 回收 item,那么 DELAYED_RECYCLED 放入的 key 是 StackA。
- 然后从 delayedRecycled 中取出 StackA 对应的 WeakOrderQueue,如果 WeakOrderQueue 不存在,那么为 StackA 新创建一个 WeakOrderQueue,并将其加入 DELAYED_RECYCLED 缓存。WeakOrderQueue.allocate() 会检查帮助 StackA 回收的对象总数是否超过 2K 个,如果没有超过 2K,会将 StackA 的 head 指针指向新创建的 WeakOrderQueue,否则不再为 StackA 回收对象。
当然 ThreadB 不会只帮助 ThreadA 回收对象,它可以帮助其他多个线程回收,所以 DELAYED_RECYCLED 使用的 Map 结构,为了防止 DELAYED_RECYCLED 内存膨胀,Netty 也采取了保护措施,从 delayedRecycled.size() >= maxDelayedQueues 可以看出,每个线程最多帮助 2 倍 CPU 核数的线程回收线程,如果超过了该阈值,假设当前对象绑定的为 StackX,那么将在 Map 中为 StackX 放入一种特殊的 WeakOrderQueue.DUMMY,表示当前线程无法帮助 StackX 回收对象。
接下来我们继续分析对象是如何被添加到 WeakOrderQueue 的,直接跟进 queue.add(item) 的源码:
1 | void add(DefaultHandle<?> handle) { |
在向 WeakOrderQueue 写入对象之前,会先判断 Link 链表的 tail 节点是否还有空间存放对象。如果还有空间,直接向 tail Link 尾部写入数据,否则直接丢弃对象。如果 tail Link 已经没有空间,会新建一个 Link 之后再存放对象,但在新建 Link 之前会检查异线程帮助回收的对象总数是否超过了 Stack 设置的阈值,如果超过了阈值,那么对象也会被丢弃掉。
对象被添加到 Link 之后,handle 的 stack 属性被赋值为 null,而在取出对象的时候,handle 的 stack 属性又再次被赋值回来,为什么这么做呢,岂不是很麻烦?如果不这么做的话,若是 Stack 不再使用,期望被 GC 回收,但JVM发现 handle 中还持有 Stack 的引用,那么Stack就无法被 GC 回收,从而造成内存泄漏。
到此为止,Recycler 如何回收对象的实现原理就全部分析完了,在多线程的场景下,Netty 考虑的还是非常细致的,Recycler 回收对象时向 WeakOrderQueue 中存放对象,而从 Recycler中 获取对象时,WeakOrderQueue 中的对象会作为 Stack 的储备,而且有效地解决了跨线程回收的问题,是一个挺新颖别致的设计。
Recycler 在 Netty 中的应用
其中比较常用的有 PooledHeapByteBuf 和 PooledDirectByteBuf,分别对应的堆内存和堆外内存的池化实现。例如我们在使用 PooledDirectByteBuf 的时候,并不是每次都去创建新的对象实例,而是从对象池中获取预先分配好的对象实例,不再使用 PooledDirectByteBuf 时,被回收归还到对象池中。
此外,内存池的 MemoryRegionCache 也有使用到对象池,MemoryRegionCache 中保存着一个队列,队列中每个 Entry 节点用于保存内存块,Entry 节点在 Netty 中就是以对象池的形式进行分配和释放。
