概述
从JDK1.7开始,Java提供Fork/Join框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
主要有两步:
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列(PS:这一点和ThreadPoolExecutor不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。如图所示:
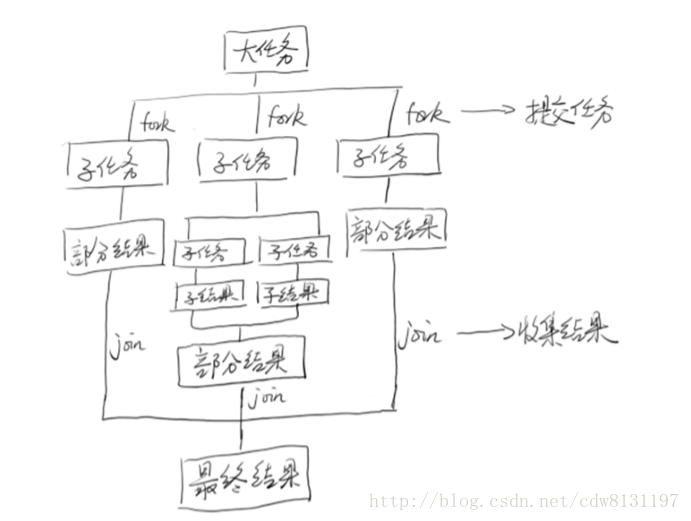
工作窃取
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
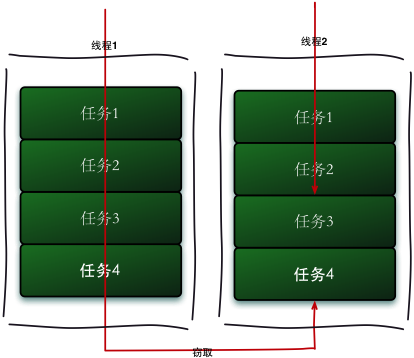
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
ForkJoinPool
该ForkJoinPool是框架的心脏。它是*ExecutorService的*一个实现,它管理工作线程(ForkJoinWorkerThread)并为我们提供工具来获取有关线程池状态和性能的信息。
实例化
在Java 8中,访问ForkJoinPool实例的最方便方法是使用其静态方法*commonPool()。顾名思义,这将提供对公共池的引用,公共池是每个ForkJoinTask*的默认线程池。
根据Oracle的文档,使用预定义的公共池可以减少资源消耗,因为这会阻止为每个任务创建单独的线程池
ForkJoinPool commonPool = ForkJoinPool.commonPool();
当然,我们也可以新建线程池
public static ForkJoinPool forkJoinPool = new ForkJoinPool(2);
使用ForkJoinPool的构造函数,可以创建具有特定级别的并行性,线程工厂和异常处理程序的自定义线程池。在上面的示例中,池的并行度为2.这意味着池将使用2个处理器核心。
ForkJoinTask
orkJoinTask是ForkJoinPool中执行的任务的基本类型。
在实践中,它的两个子类之一应该被继承:*RecursiveAction返回值为空,RecursiveTask *有返回值。
它们都有一个抽象方法*compute()*,其中定义了任务的逻辑,也就是要覆写的方法。
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| public class ForkJoinTaskDemo {
private class SumTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 20;
private int arr[];
private int start;
private int end;
public SumTask(int[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
private Integer subtotal() {
Integer sum = 0;
for (int i = start; i < end; i++) {
sum += arr[i];
}
System.out.println(Thread.currentThread().getName() + ": ∑(" + start + "~" + end + ")=" + sum);
return sum;
}
@Override
protected Integer compute() {
if ((end - start) <= THRESHOLD) {
return subtotal();
}else {
int middle = (start + end) / 2;
SumTask left = new SumTask(arr, start, middle);
SumTask right = new SumTask(arr, middle, end);
left.fork();
right.fork();
return left.join() + right.join();
}
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
int[] arr = new int[100];
for (int i = 0; i < 100; i++) {
arr[i] = i + 1;
}
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> result = pool.submit(new ForkJoinTaskDemo().new SumTask(arr, 0, arr.length));
System.out.println("最终计算结果: " + result.invoke());
pool.shutdown();
}
}
ForkJoinPool.commonPool-worker-2: ∑(50~62)=678
ForkJoinPool.commonPool-worker-2: ∑(62~75)=897
ForkJoinPool.commonPool-worker-2: ∑(75~87)=978
ForkJoinPool.commonPool-worker-2: ∑(87~100)=1222
ForkJoinPool-1-worker-1: ∑(0~12)=78
ForkJoinPool-1-worker-1: ∑(12~25)=247
ForkJoinPool-1-worker-1: ∑(25~37)=378
ForkJoinPool-1-worker-1: ∑(37~50)=572
ForkJoinPool-1-worker-2: ∑(75~87)=978
ForkJoinPool-1-worker-3: ∑(50~62)=678
ForkJoinPool-1-worker-5: ∑(62~75)=897
ForkJoinPool.commonPool-worker-7: ∑(0~12)=78
ForkJoinPool.commonPool-worker-3: ∑(37~50)=572
ForkJoinPool-1-worker-4: ∑(87~100)=1222
ForkJoinPool.commonPool-worker-2: ∑(25~37)=378
ForkJoinPool.commonPool-worker-5: ∑(12~25)=247
最终计算结果: 5050
|
结论
使用fork / join框架可以加速处理大型任务,但要实现这一结果,应遵循一些指导原则:
- 使用尽可能少的线程池 - 在大多数情况下,最好的决定是为每个应用程序或系统使用一个线程池
- 如果不需要特定调整,请使用默认的公共线程池
- 使用合理的阈值将ForkJoingTask拆分为子任务
- 避免在 ForkJoingTasks中出现任何阻塞
